What's the difference between GPT-3 and Chat GPT? OpenAI's code-davinci-2 and text-davinci-3 models? A short primer.
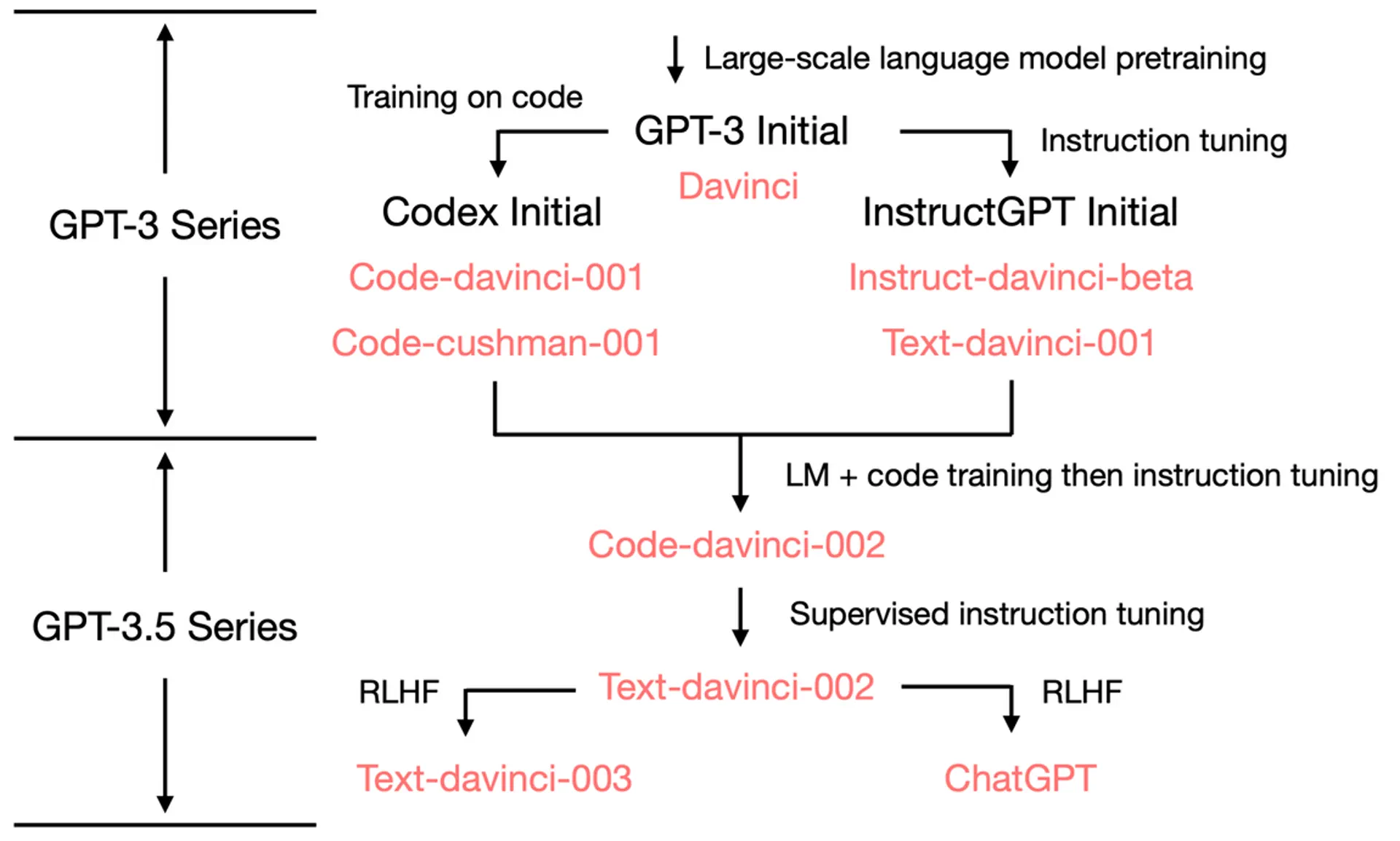
The initial GPT-3 (2020) is known as "davinci" in OpenAI's API models. You can see this post to see what it was trained on.
InstructGPT introduced fine-tuning through human-written demonstrations and "instruction tuning." This was done to solve the problems of (1) hallucination and (2) instruction following. The OpenAI authors talk about the trade-off between performance and the ability to follow instructions and call this the "alignment tax" – the fine-tuned model is better at following common instructions but worse overall, given academic performance benchmarks.
Codex (the model that powers GitHub Copilot) was fine-tuned from a GPT-3 series model but with the addition of adding the GitHub code corpus.
Combining both the instruction tuning form InstructGPT and Codex yielded a new model code-davinci-002, which is the basis for both the state of the art text-davinci-003 and ChatGPT.
The last iterations of GPT-3.5 models have improved mostly through supervised or reinforcement learning, i.e., giving the models feedback on what is good and bad output.
Maybe the most important consideration of all this is how much training on code increased the model's "chain-of-thought" reasoning – or ability to perform complex logical steps. None of the models before Codex (including InstructGPT) had this ability. There's something special about code that increases the model's NLP capabilities.